
ViT의 중요특징 3가지
1.
이미지 패치(patch)를 단어처럼 다루었다.
2.
아키텍처는 Transformer의 Encoder 부분이다.
3.
거대한 데이터 세트인 JFT-300M으로 사전학습(pre-train)하였다.

ViT 전체 과정
1.
이미지를 먼저 16x16 크기의 patch로 분할하고 linear projection을 통해 1차원으로 Flatten한 벡터를 D차원으로 변환하여 이를 patch embedding으로 사용한다.
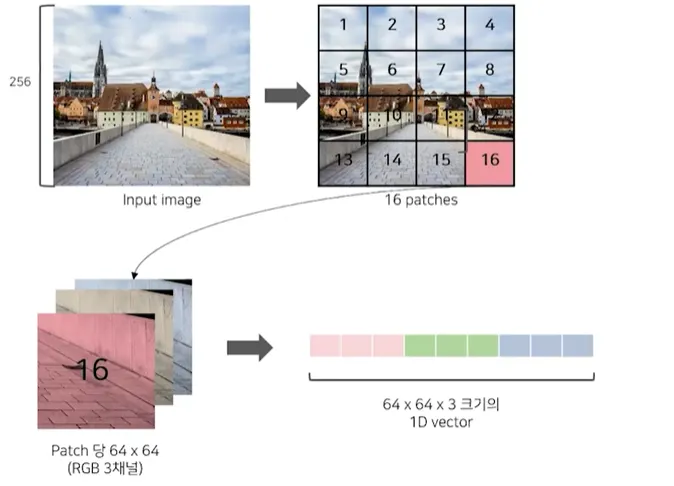
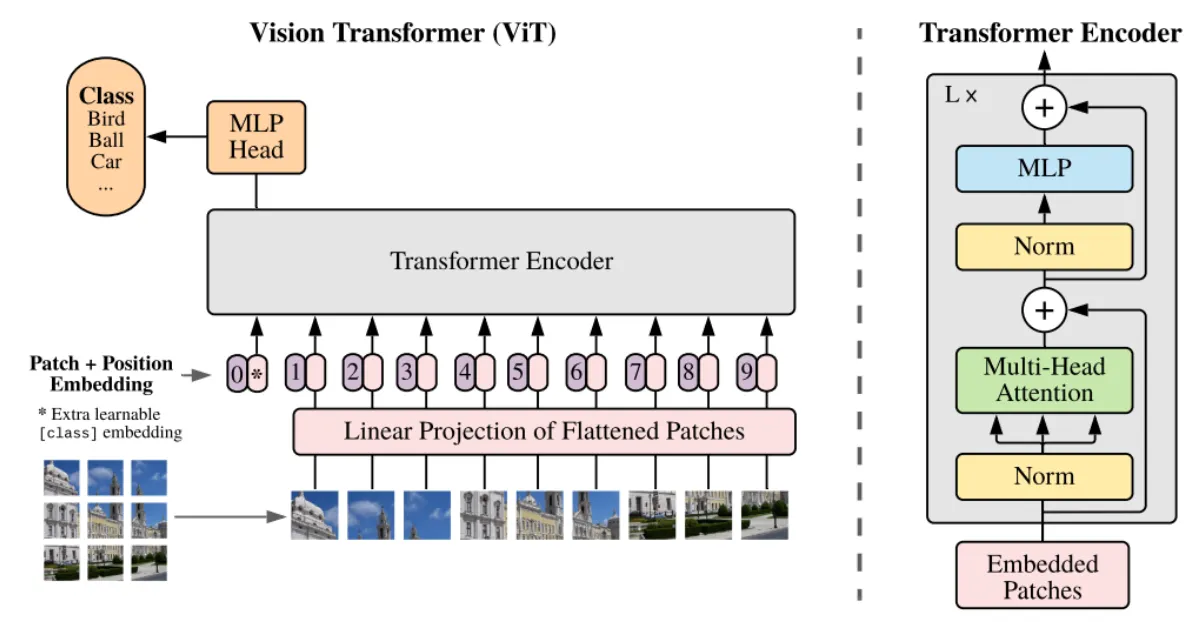
2.
Class embedding([CLS])과 patch embedding에 position embedding을 더하게 된다.
3.
이를 인코더에 input으로 넣어, 마지막 layer에 class embedding에 대한 output인
image representation을 도출한다.
4.
이것을 MLP Head에 넣어서 클래스를 분류하게 된다.
•
[CLS] : classification을 사용하기 위해 사용되는 토큰이다.
•
[CLS] 와 position embedding 모두 학습 가능한 토큰이다.
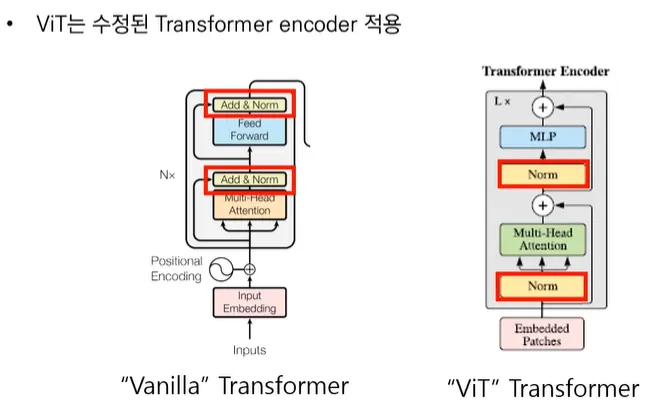
•
기존 Vanilla Transformer와는 다르게 Encoder내에서 Layer Normalization의 위치를 바꾸었다.
→ 깊은 layer에서도 학습이 잘되는 효과를 얻었다.
(이때 LN은 D차원 방향으로 각 feature에 대하여 정규화를 진행한다.)
•
MLP는 2개의 FC layer로 되어있으며, 특이하게도 GELU 활성화 함수를 사용한다.

는 linear Projection을 하기 전의 flatten된 patch들이다.
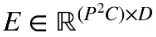
는 Linear Projection할 때 쓰이는 행렬이다.
이때 는 Embedding dimension이다.
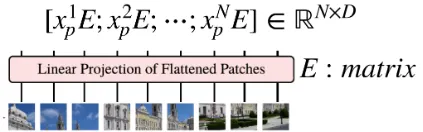
의 shape은 ( ),
의 shape은 ( )으로 곱 연산(=Linear Projection)을 하면,
output은 () 크기의 행렬이 된다.
* 이때 N은 나뉘어진 패치의 개수이다.
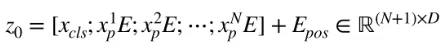
N개의 input에 에 [CLS] token까지 끼워 붙여서 행은 (N+1)이고 열은 D차원이다.
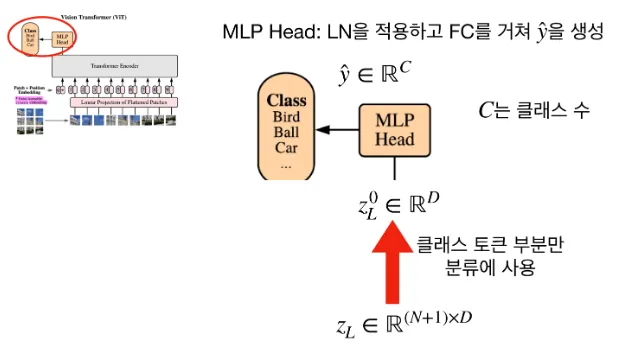
인코더의 마지막 출력에서 class token 부분만 분류 문제에 사용하게 되며 MLP Head에 넣어 D차원을 C차원(=num_classes)으로 바뀌게 된다.