

정의: 큰 네트워크(Teacher 모델)로부터 작은 하나의 네트워크(Student 모델)에 지식을 전달하는 기법. 즉 복잡한 모델이 학습한 generalization 능력을 단순한 모델에게 transfer 해주는 것이다.
* Transfer learning와는 달리 같은 도메인 내의 지식을 전달하는 방식이다.

Knowledge Distillation의 주된 목적은 높은 성능을 가진 복잡하고 무거운 딥러닝 모델의 지식을, 더 가벼운 모델로 전달하는 것이다. 이러한 접근 방식은 여러 측면에서 효율성을 높일 수 있다.
1.
컴퓨팅 리소스: 복잡한 모델은 일반적으로 높은 계산 능력을 요구한다. 가벼운 모델을 사용하면, GPU나 CPU의 부하를 줄여 컴퓨팅 리소스를 효율적으로 활용할 수 있다.
2.
배터리 소모: 모바일 장치에서 복잡한 모델을 실행하면 배터리 소모가 빠를 수 있다. 가벼운 모델은 이러한 문제를 완화할 수 있다.
3.
메모리 사용량: 더 작은 모델은 더 적은 메모리를 사용한다. 이는 메모리 제한이 있는 장치에서 특히 중요하다.
4.
배포 용이성: 실제 서비스 환경에서는 모델의 크기와 복잡성이 종종 제한적이다. 특히 모바일 장치나 엣지 컴퓨팅 환경에서는 강력한 하드웨어가 제한적일 수 있다. 이런 상황에서 Knowledge Distillation을 통해 얻은 가벼운 모델은 배포가 더 쉽고 효율적이다.

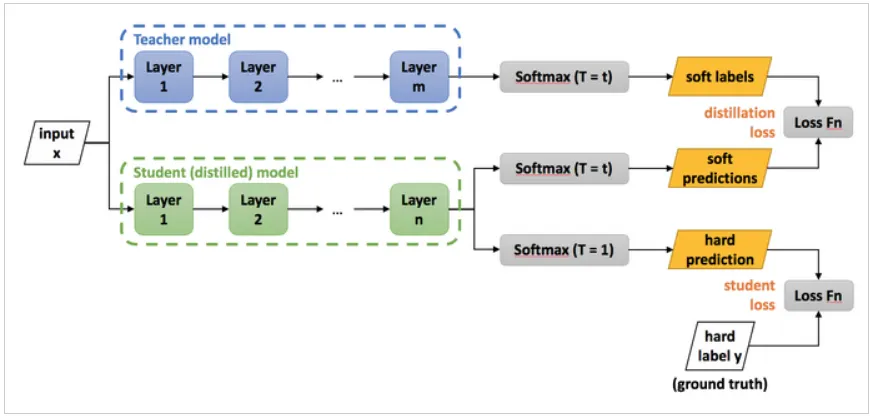
Loss function은 student loss와 distillation loss가 있다.

•
α 는 두 loss에 대한 가중치이다. 무슨 Loss를 더 중요하게 학습할 건지 판단하는 파라미터이다.
•
는 Temperature로 극단적으로 Softmax 값이 차이나게 되는 것을 막아주는 파라미터이다.
Hard label을 하게 되면 일부 class에 대한 확률값은 0에 가까운데, 이는 학습 시에 지식이 잘 전달되지 않게 된다. → T를 통해 Soft label으로 만들어 준다.
T가 높으면 → 비슷비슷하게, T가 작으면 → 하나만 뚜렷하게 된다.
(T는 보통 2~5 사이의 값을 사용한다고 한다.)
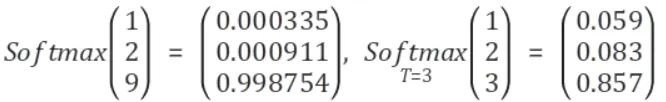
또한 T는 output을 더 soft하게 만들어주기 때문에 overfitting을 방지하는 효과도 있다.
모델의 parameter가 많을수록 overfitting될 가능성이 높은데 T가 그걸 막아준다.
두 가지 Loss 설명
전체 학습 과정
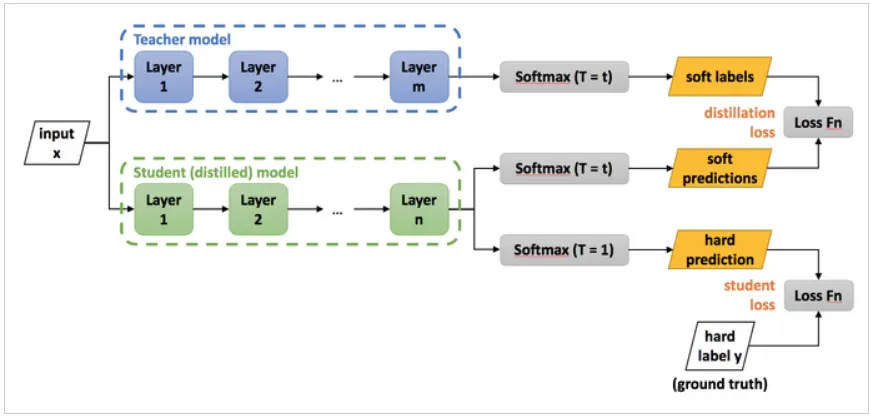
1.
Teacher Network 학습
training set(input, hard label)을 이용해 large model을 학습한다. (사전에 미리 해놓는다.)
이후에 T를 이용하여 soft labels를 생성한다.
2.
Student Network 학습
input과 앞서 구한 soft label로 transfer set을 생성한다.
transfer set은 두가지 prediction에 쓰이고 small model을 학습한다.
아까와 똑같은 T를 사용하여 soft predictions 도출
이번엔 T 없이 hard predictions 도출
3.
distillation loss 구성
soft labels와 soft predictions로 KL Divergence를 통해 구한다.
4.
student loss 구성
hard prediction과 hard label로 Cross-Entropy를 통해 구한다.
5.
두 loss를 더한 최종 loss를 통해 모델 갱신